Здесь представлены графические визуализации имён годвилльского контента - "семантические облака". Те, кто хочет узнать детали алгоритма, пусть читают текст до конца. Для остальных же скажу лишь, что это способ преобразования слов в вектора ("эмбеддинги") с их последующей проекцией на плоскость. Упрощённо можно считать, что чем ближе сходство между словами, тем ближе их вектора. Рисунок состоит из центрального слова, выделенного красным, и двадцати ближайших к нему слов, выделенных синим. В заголовке графика можно видеть два числа в скобках: чем они больше, тем меньше сходство между словом и его соседями, то есть тем оно оригинальнее.
Вот, например, визуализация имени монстра "Скупой Рыцарь":
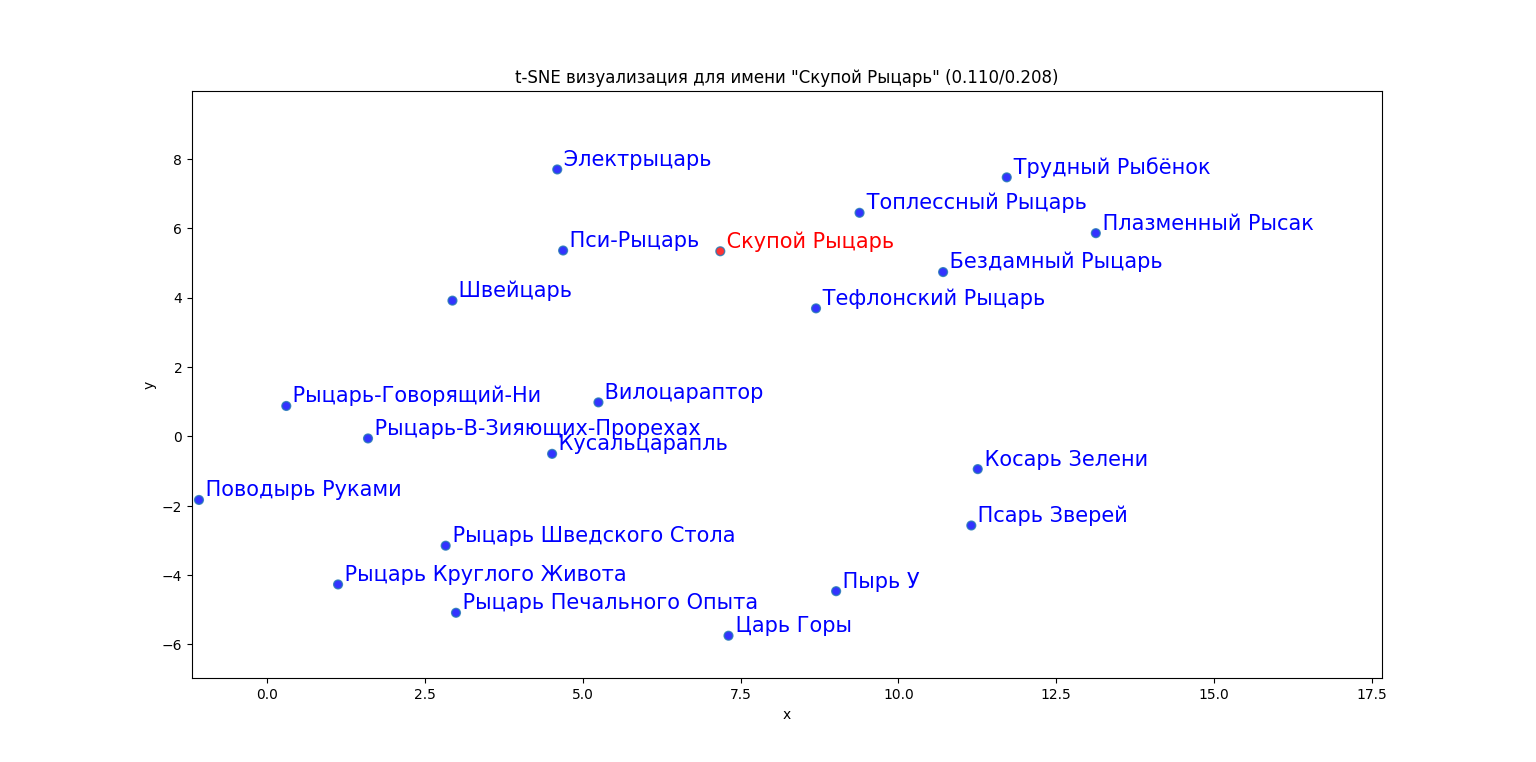
Мы видим, что окружён он в основном различными рыцарями (Пси-Рыцарь, Топлессный рыцарь, Электрыцарь и т.д.), но в компанию ближайших соседей попали также слегка созвучные Плазменный Рысак, Трудный Рыбёнок, Царь Горы ("(ры)царь") и даже Косарь Зелени ("косарь - царь - рыцарь").
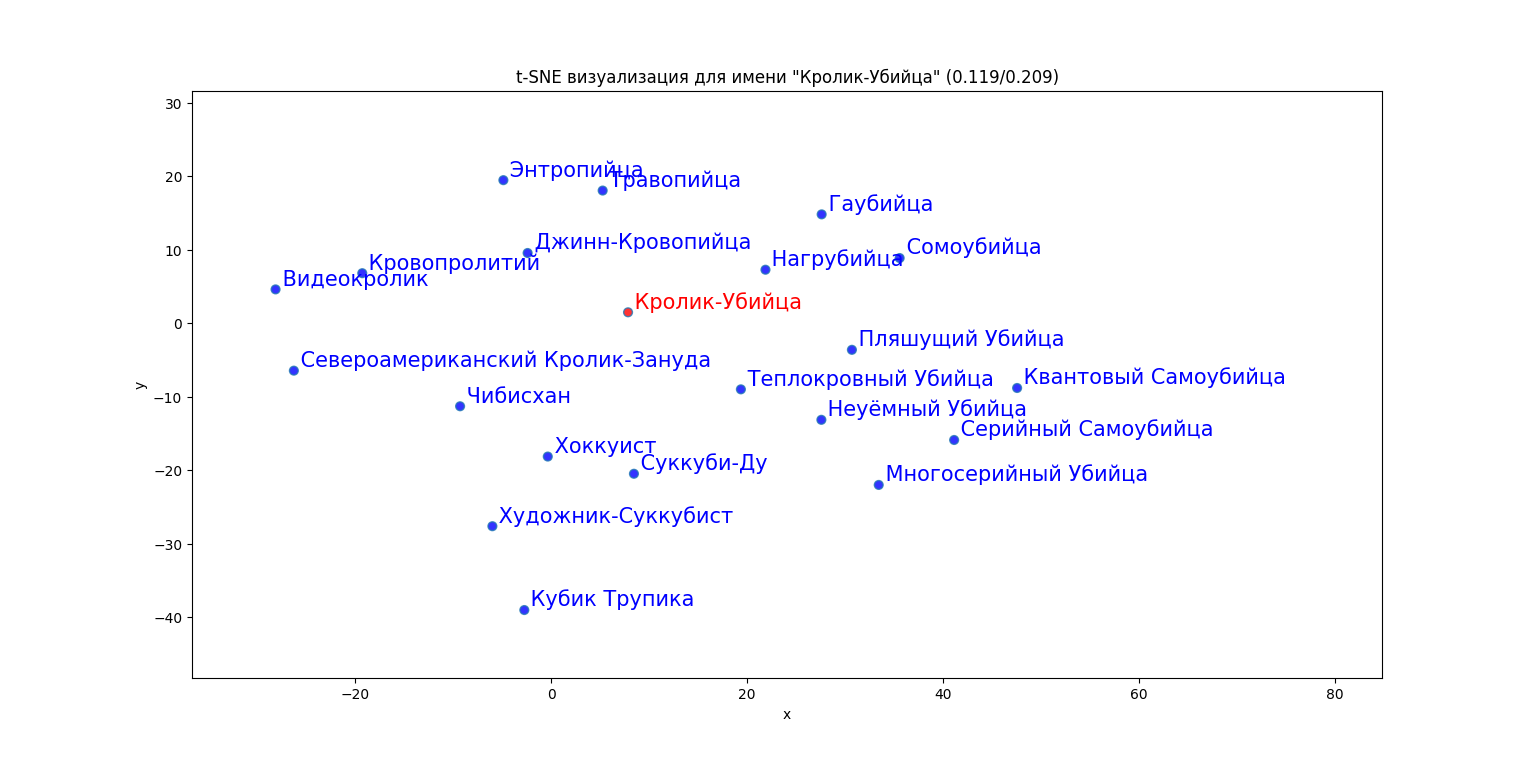
Кролика-Убийцу окружают кролики, убийцы и разные другие -ийцы, но в соседи, по каким-то ассоциациям, попали Кровопролитий и Кубик Трупика.
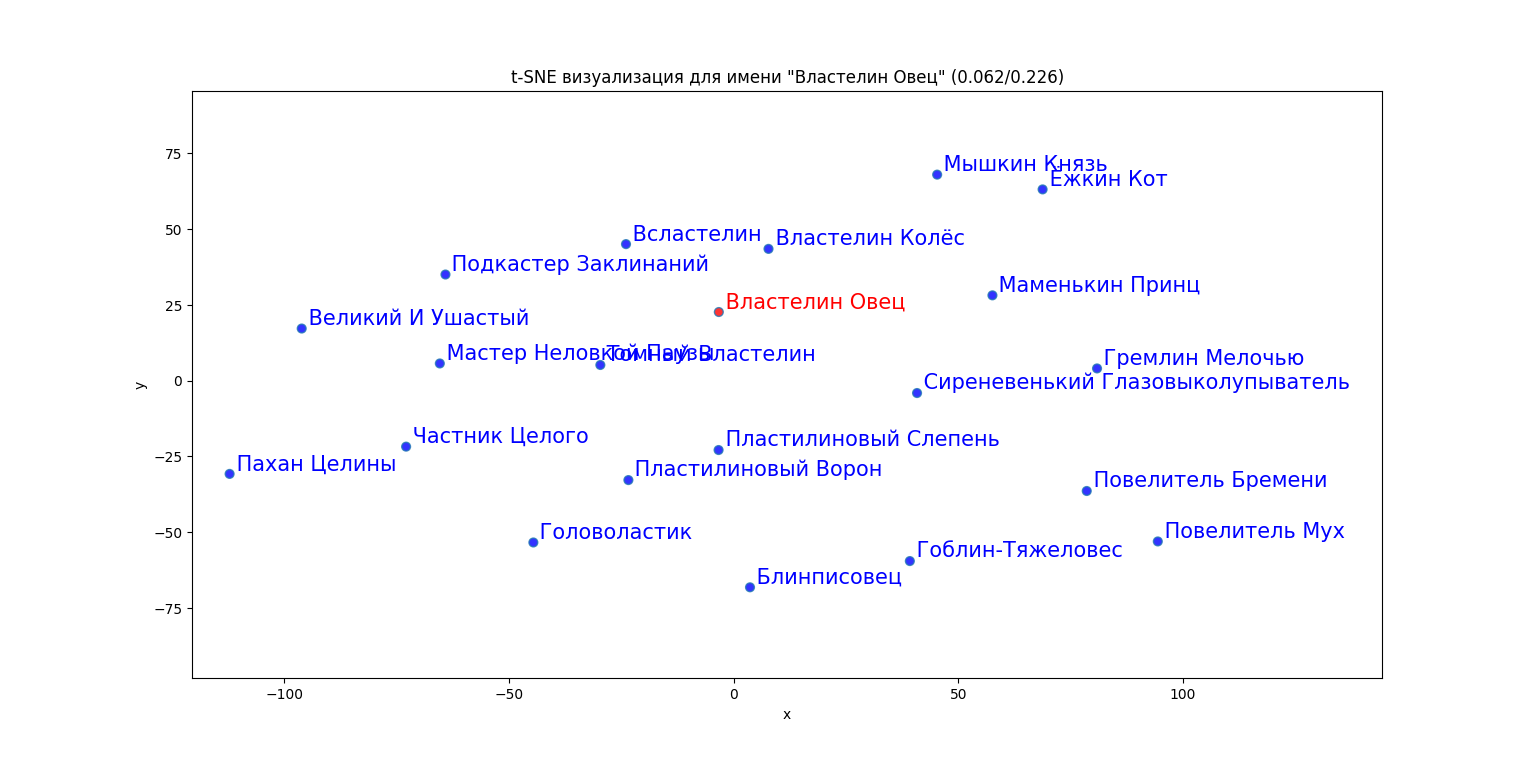
Иногда алгоритм вылавливает и менее тривиальные сходства семантики. Например, у Властелина Овец в соседях оказались Великий И Ушастый, Повелитель Мух, Мышкин Князь, Маменькин Принц. Мастер Неловкой Паузы, Пахан Целины... То есть личности выдающиеся, в том или ином смысле, и (или) коронованные
И ещё несколько семантических тучек:
Теперь - обещанное, более формальное описание, алгоритма: